
 03-31-2026
03-31-2026 




|
Getting your Trinity Audio player ready...
|
Almost 12 years ago, this forum post asked whether Bitcoin creator Satoshi Nakamoto objected to embedding data in the blockchain. Today, this is still a heavily debated question, as three SHA-256 forks still exist with varying views on the topic. Furthermore, the Ordinals innovation on BTC has added more fuel to these debates as it is entirely predicated on embedding arbitrary data into the blockchain.
Let us look at the evidence for support and opposition of data on-chain.
Support
First, Satoshi’s Bitcoin script, specifically the OP_PUSHDATA4 opcode, allowed up to 4.3 GB of data to be pushed onto the stack. Ordinals creator Casey Rodarmor even pointed this out to further justify the protocol’s existence.
You could have done 4 gig OP_RETURN inscriptions in Satoshi's original client.
— Casey (@rodarmor) May 29, 2023
Satoshi wrote that he “wanted to design it (Bitcoin) to support every possible transaction type I could think of.” Despite this, at the end of 2010, Satoshi implemented the IsStandard() check, which only permitted a few transaction types, on the premise that new commonly used transaction types that gain adoption could be easily whitelisted in the future. At that time, a relevant discussion around BitDNS was ongoing in parallel, where Satoshi stated he supported “a third transaction type for timestamp hash sized arbitrary data.”
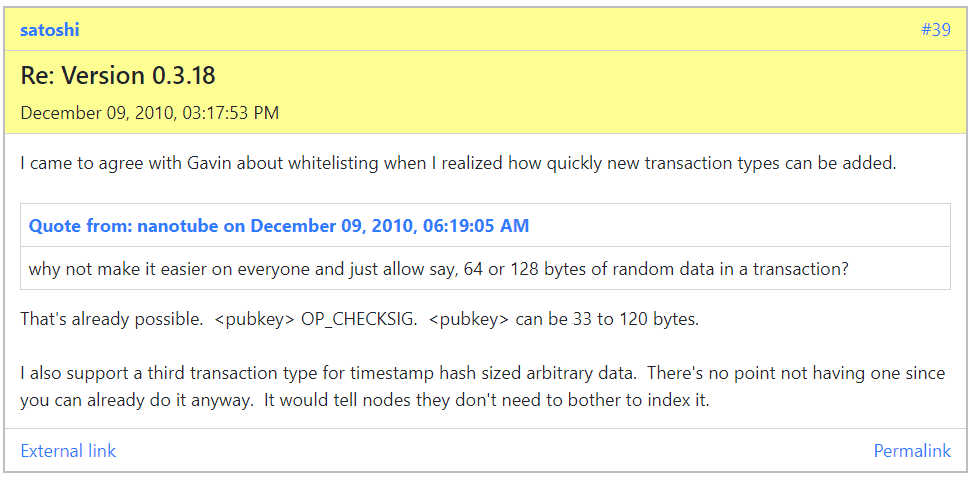
Opposition
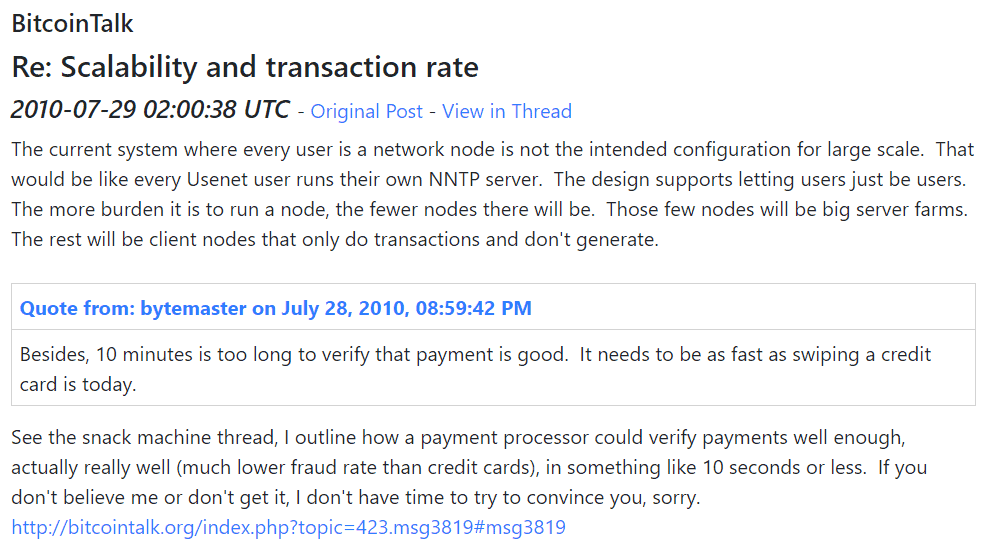
Perhaps the strongest opposition Satoshi expressed against data on-chain was in that same BitDNS discussion that “Piling every proof-of-work quorum system in the world into one dataset doesn’t scale.” Additionally, he stated while BitDNS users may want “large data features” that Bitcoin users “might get increasingly tyrannical about limiting the size of the chain so it’s easy for lots of users and small devices.” Naturally, that last statement is gasoline for the small block, decentralized narrative that caused the first split in August 2017. Interestingly, Satoshi thought the BitDNS network should be a separate blockchain (i.e., sidechain) that was still derived from and linked to the base Bitcoin chain in terms of proof-of-work.
However, the above quote, isolated from the context of BitDNS and proof-of-work, contradicts one of Satoshi’s most famous quotes about the fate of the network only having “few nodes” that are “big server farms.”
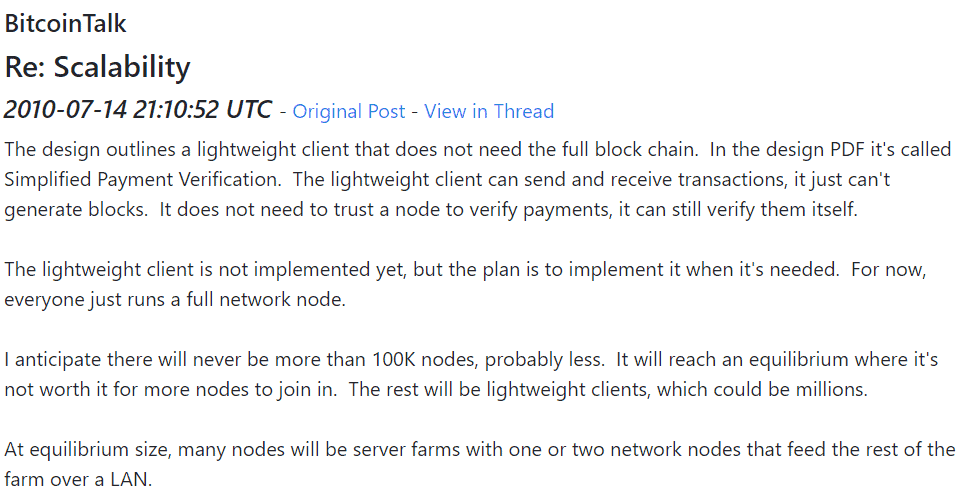
In another related thread the same day, he states that the Bitcoin “design outlines a lightweight client does not need the full block chain.” The “client can send and receive transactions, it just can’t generate blocks.”
Conclusion
Satoshi clearly intended Bitcoin to be used for all types of transactions but did not necessarily think that large data payloads should be included. He did program script to allow such large data, but seemed to believe hashing data was more prudent, as he agreed with Hal Finney.
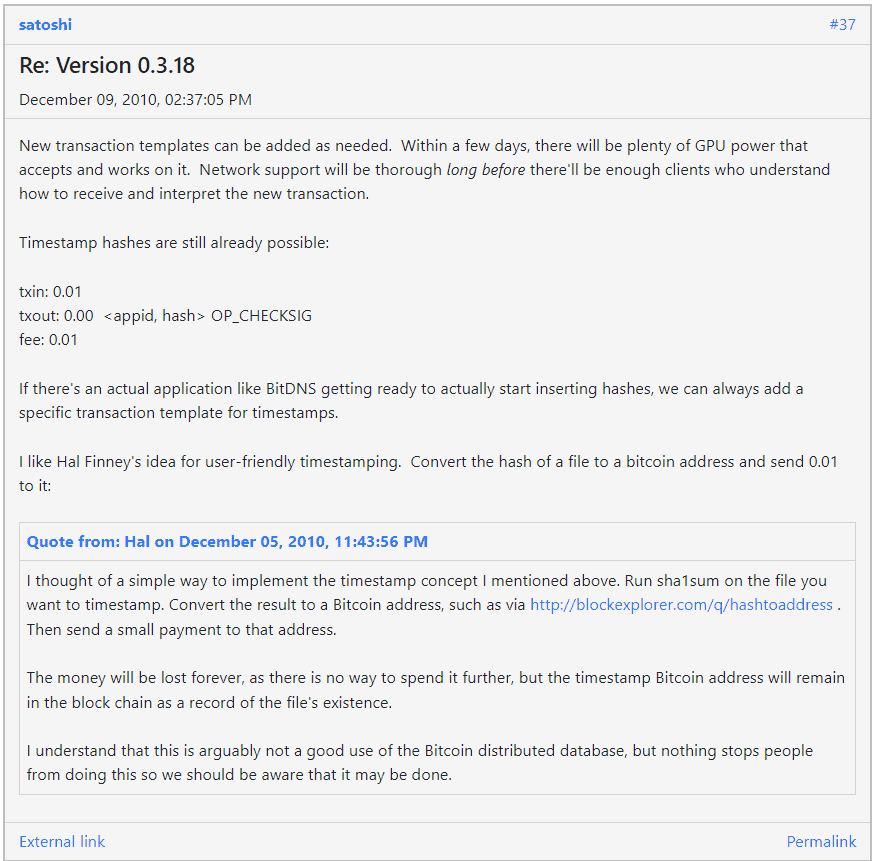
Funnily enough, the above solution is similar to the OP_RETURN method of embedding data on-chain into 0-Satoshi un-spendable outputs, such that the UTXO set is not bloated with data. Note that the above solution cannot be pruned, whereas 0-satoshi OP_RETURN outputs can be.
His quote on BitDNS should be considered in context, not as an overall, overt criticism to data on-chain, as he clearly sees user clients to implement SPV, or lightweight clients, and only manage their own transactions, not be burdened by unrelated protocols such as BitDNS.
Satoshi seemed to prefer embedded hashes of data as a more economical solution compared to embedding entire files on the blockchain. While his protocol technically supported the latter, he likely considered the former a more technically sound and efficient means of doing so.
What do the readers think? Would Satoshi have favored one method over the other, given how Bitcoin has been adopted today?
Recommended for you



