
 07-18-2026
07-18-2026 




|
Getting your Trinity Audio player ready...
|
hodlnet.sh launches as a search engine for locked content. The announcement was made on hodlocker on the last Sunday of October 2023 by anonymous developer shrdlu2. At first, this appears to be a simple search of all posts made on hodlocker.com, but actually, you can search any content on the blockchain that has or has had any locked amount of satoshis against it.
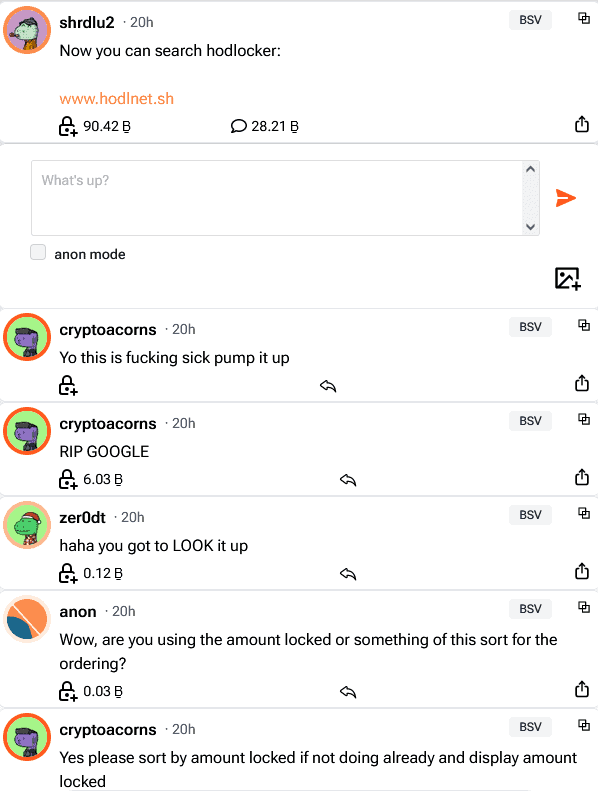
At first blush, claims of surpassing Google (NASDAQ: GOOGL) seem absurd, but one must analyze the implications at scale. Google indexes content based on its proprietary, subjective algorithm, which has an inherent bias. By indexing content against satoshis, the ranking search results remain objective.
While the content ranked by satoshis is indeed subjective, the ranking algorithm is objective. Also, the data is publicly available on the blockchain, not stored in private servers, which means other services can implement search with different queries, but all services are working with the same data set and ranking criteria. Users are free to interpret that data however they like.
For example, the same search on Bing and Google returns different results:
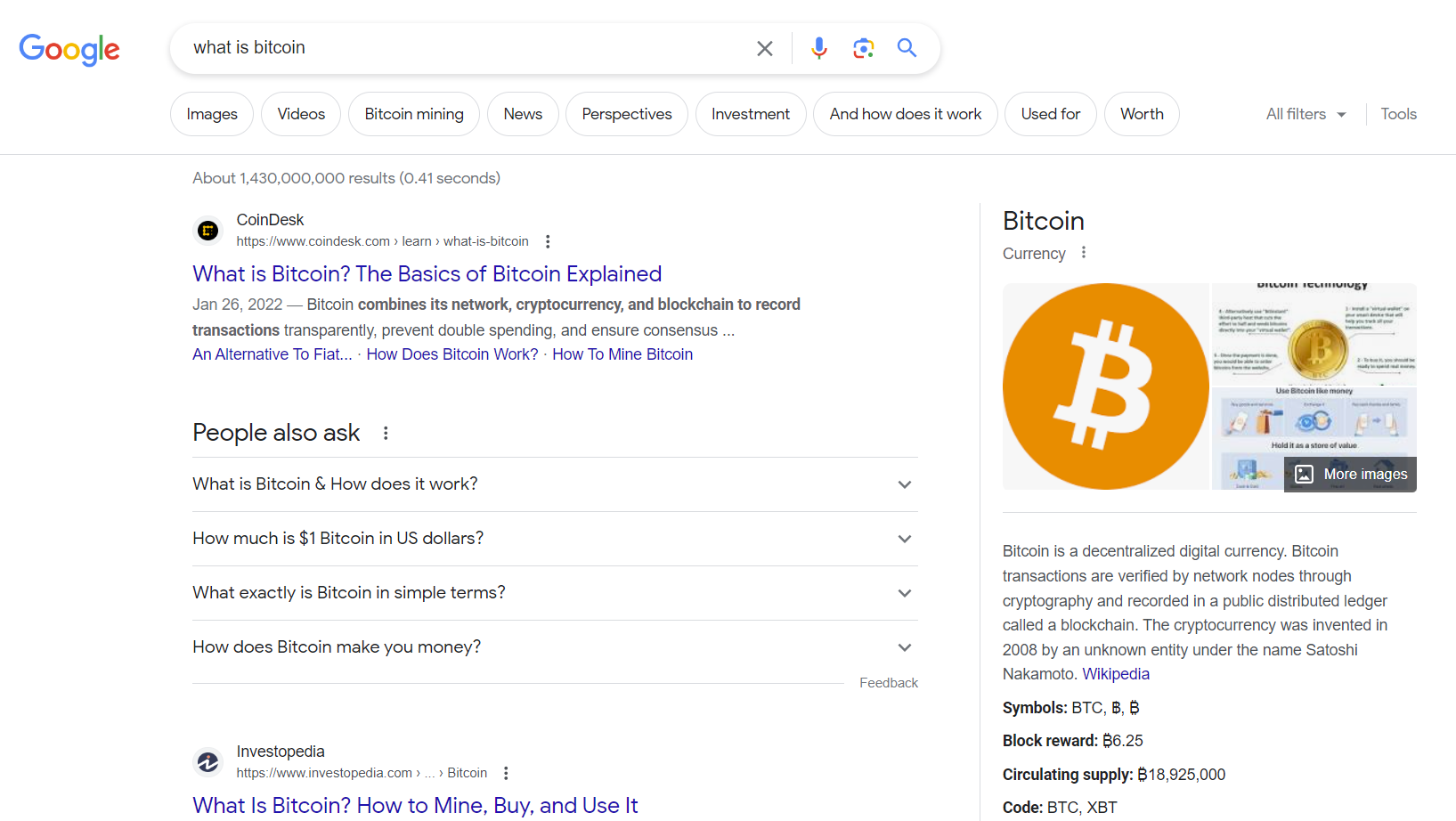
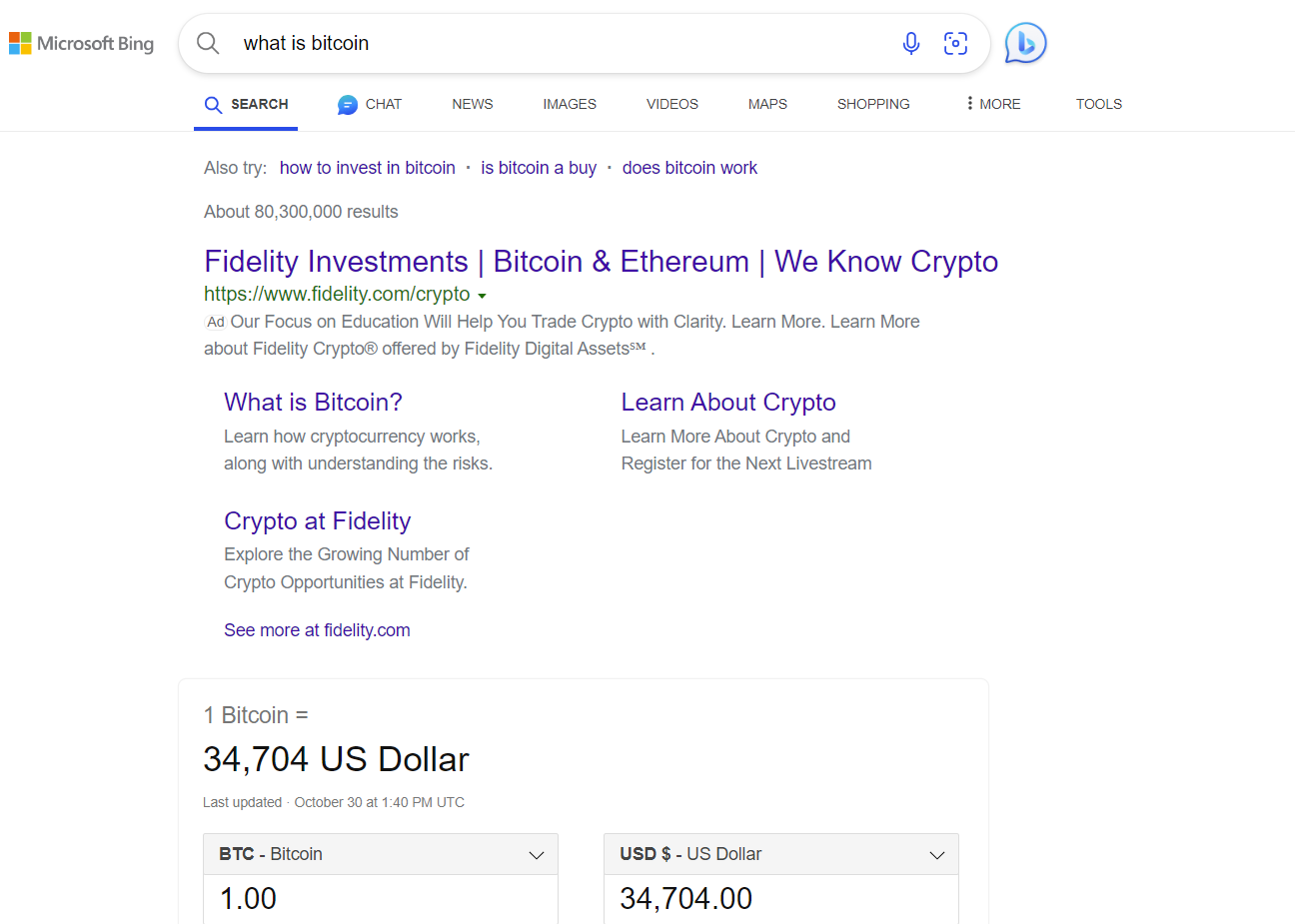
By using satoshis and time locks to index content, the search engines can stay lean yet efficient. They do not need to index the entire blockchain at any given time, instead only indexing the content with active locking. Services can prune data that is no longer relevant, meaning its nLockTime has expired. Notice the search on hodlnet is instant. One may think this is because there are so little transactions in the chain, but this data scales with the satoshis locked. Additionally, thresholds can be set so that only data with 0.01 BSV are indexed. A specific service could choose to only index expired posts so users can go searching in the archives for older data.
Conversely, this means that relevant data at that point in time will appear at the top of the query when ranked by the amount of satoshis locked. Moreover, while this is not implemented yet, users will be able to search for data at a specific point in time for the most relevant data at that point in time, features that are unavailable in the top search engines today. For example, if locked content had been implemented since Bitcoin’s Genesis block, a search of “Bitcoin” on hodlnet would have returned very different results in 2010 than in 2023.
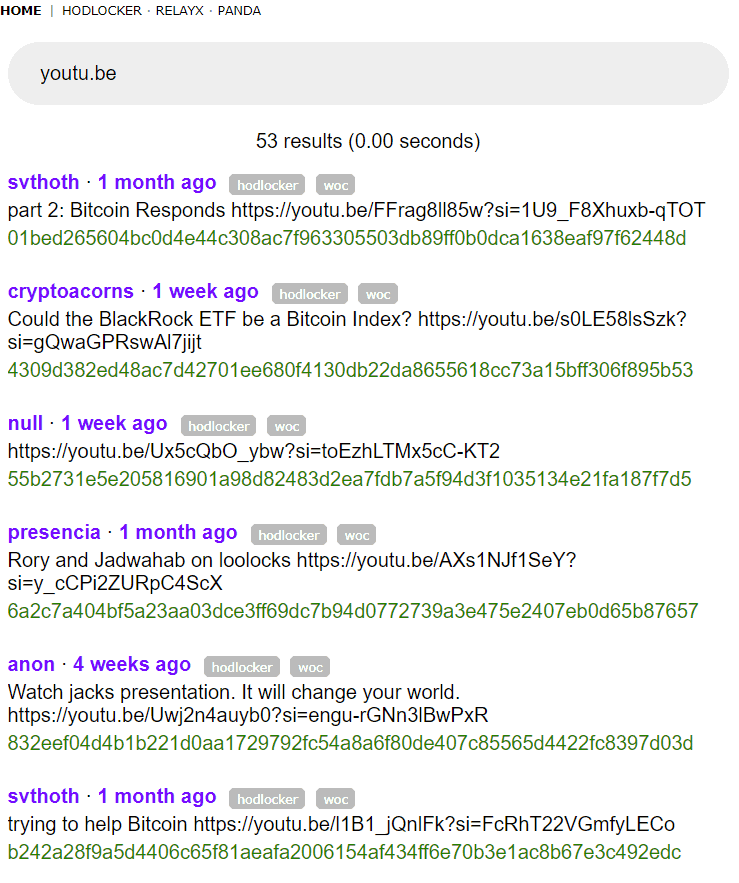
The implication is queries such as “youtu.be” will yield the top-ranked YouTube videos at that point in time. If I want to find the best R&B songs in 1995, I’d have to search YouTube with that query and the specific year, relying on users to have manually tagged the content appropriately. On a hodlnet search service, I could simply search #music, #r&b and get only tracks that had locking across the entire year 1995.
The dynamic dimensions and data points simply cannot be offered by existing Web 2.0 search engines. With locking, we can interestingly observe how humans ranked content over time, not just today. Only the economic incentives, scale, and computational script of Bitcoin as originally designed enable this new model of information curation.
Watch The Bitcoin MasterClasses Workshop #2: Using time-locked DFAs for processes
Recommended for you



