


The internet community can be a funny place. If you’re at all a public figure, you can expect to be spat at, ridiculed, accused, and pretty much deemed guilty before any conclusivity.
Dr Craig S Wright is no stranger to being on the receiving end in this manner. Entrenched in a world where every keyboard warrior believes they are judge, jury, and executioner can be taxing. But the burden of proof should always lie with the accuser.
One of the most prominent of websites out there today that many rely on for evidence of sorts, is the “WayBackMachine” – famously known as the “Internet Archive”. If there are any doubts as to the authenticity of a publication date, internet users will flock to http://web.archive.org/ and quickly assess the date of publication, as captured by WayBackMachine’s crawler, snapshotted into its archives.
Certainly, many claims that have been made against Dr Wright place heavy reliance on this tool. Claims that he maliciously backdated information, and attempted to conceal evidence are peppered on forums every time the spectre and possibility of Craig Wright being Satoshi surfaces.
But how much trust should we place on such services and their capacity to provide accurate information in this regard?
The first and most obvious detail to note, is that WayBackMachine is not some immutable database that is resistant to change and modification.
But more interestingly, is this second point: The behaviour of WayBackMachine can be to some degree, piloted by webmasters themselves.
This isn’t some voodoo magic. It is search engines, and archiving tools such as WayBackMachine, functioning as designed. Web developers are very familiar with this concept, but it is very possible (in fact its blindingly easy!) to omit a particular page from appearing in WayBackMachine (or google for that matter), for a defined period of time, simply by placing a couple of meta-tags within the HTML header of a webpage.
Let’s take this opportunity, to see just how easy it is for anyone, to manipulate and control their webpage snapshots, on a site like WayBackMachine.

The above meta-tag in bold instructs most search engines not to index the page. Most search engines therefore, will not show the webpage in their search results.
Further X-Robots-Tag can also be used an element of the HTTP header response for a given URL.
Take the following example as a response:
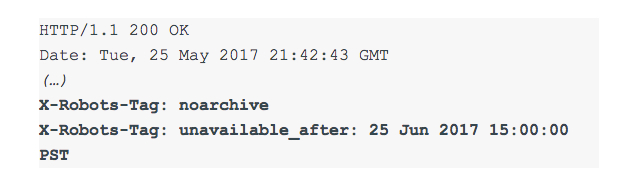
Now the above will do two things.
The “noarchive” directive will prevent a search engine from creating a “cached” copy of the site. The “unavailable_after” directive ensures that the page does not show up in search results after a specified date and time.
The two directives together are able to completely remove a webpage off-record until a specified date, throwing into question the entirety of the “he created the page in 2014/15” argument.
Simply put, these tools index and cache webpage content in a manner as requested by an author.
Does Dr Wright use such meta-tags in his posts?
His response: “It’s my right to privacy”.
Sure enough, many of the pages that are linked externally from 2011, only show up on the WayBackMachine archive in 2015
Perhaps machines can tell us many things… Much of which can be useful, and usable. But without knowing the ins and outs of any tool, it would be foolish to treat the output of any such tool as conclusive evidence. Search engines, and archivers of this nature are tools to assist both search engine users, SEO specialists, webmasters and web developers. They are not ‘designed’ as a forensic tool.
Further information on the usage of Robot meta tags, you can view Google’s own documentation on the topic here.
Eli Afram
@justicemate
New to blockchain? Check out CoinGeek’s Blockchain for Beginners section, the ultimate resource guide to learn more about blockchain technology.





